728x90
반응형
설치환경
윈도우 11 WLS2 Ubuntu 22.04
참고 블로그 : https://netmarble.engineering/docker-on-wsl2-without-docker-desktop/
1. 사전 작업
nvidia 설치 블로그 : https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html#docker
- 패키지 목록 업데이트 & 드라이버 설치
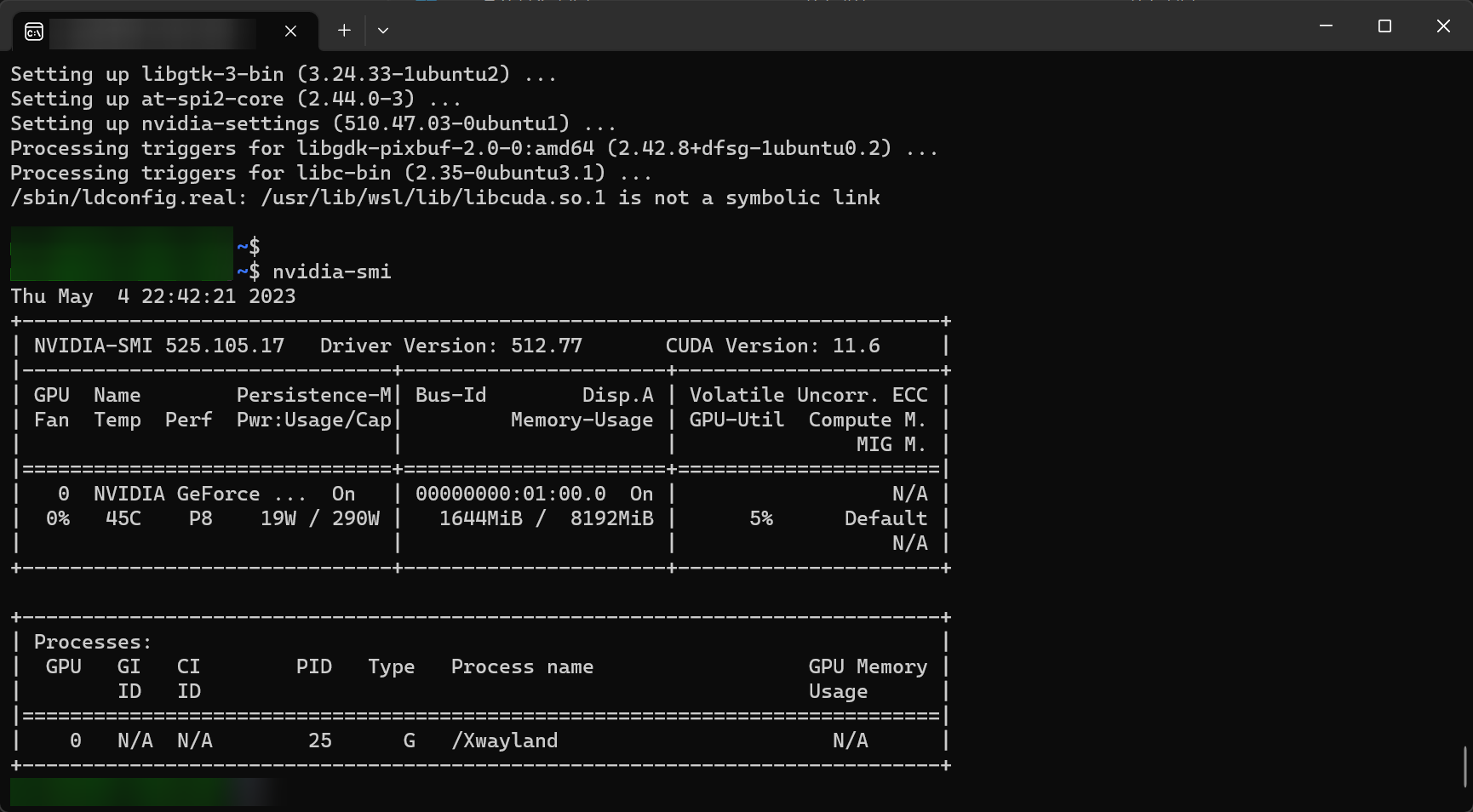
도커 설치
curl https://get.docker.com | sh \
&& sudo systemctl --now enable docker- 패키지 저장소 및 GPG키 설정
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \ && curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \ && curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | \ sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \ sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
- 패키지 설치
sudo apt-get install -y nvidia-container-toolkit- NVIDIA Container Runtime을 인식하도록 Docker 데몬을 구성
sudo nvidia-ctk runtime configure --runtime=docker- 기본 런타임을 설정한 후 Docker 데몬을 다시 시작하여 설치를 완료
sudo systemctl restart docker- 기본 CUDA 컨테이너를 실행하여 작업 설정을 테스트
sudo docker run --rm --runtime=nvidia --gpus all nvidia/cuda:11.6.2-base-ubuntu20.04 nvidia-smi- 아래와 같이 콘솔 출력이 표시됨 - 끝

sudo apt install nvidia-cuda-toolkit2. TabbyML 설치
docker run
\--gpus all
\-it
\-v "/$(pwd)/data:/data"
\-v "/$(pwd)/data/hf\_cache:/home/app/.cache/huggingface"
\-p 5000:5000
\-e MODEL\_NAME=TabbyML/J-350M
\-e MODEL\_BACKEND=triton --name=tabby tabbyml/tabby오류메세지
2023-05-02 10:00:00,660 DEBG 'triton' stderr output:
I0502 10:00:00.659909 647 pinned\_memory\_manager.cc:240\] Pinned memory pool is created at '0x2034e0000' with size 268435456
I0502 10:00:00.660035 647 cuda\_memory\_manager.cc:105\] CUDA memory pool is created on device 0 with size 67108864
2023-05-02 10:00:01,662 INFO success: triton entered RUNNING state, process has stayed up for > than 1 seconds (startsecs)
^Z^C
2023-05-02 10:00:04,886 DEBG 'triton' stderr output:
I0502 10:00:04.886509 647 model\_lifecycle.cc:459\] loading: fastertransformer:1
2023-05-02 10:00:05,002 DEBG 'triton' stderr output:
I0502 10:00:05.002126 647 libfastertransformer.cc:1828\] TRITONBACKEND\_Initialize: fastertransformer
I0502 10:00:05.002167 647 libfastertransformer.cc:1838\] Triton TRITONBACKEND API version: 1.10
I0502 10:00:05.002171 647 libfastertransformer.cc:1844\] 'fastertransformer' TRITONBACKEND API version: 1.10
I0502 10:00:05.002203 647 libfastertransformer.cc:1876\] TRITONBACKEND\_ModelInitialize: fastertransformer (version 1)
2023-05-02 10:00:05,004 DEBG 'triton' stderr output:
I0502 10:00:05.002877 647 libfastertransformer.cc:372\] Instance group type: KIND\_CPU count: 1
I0502 10:00:05.002903 647 libfastertransformer.cc:402\] Sequence Batching: disabled
I0502 10:00:05.002906 647 libfastertransformer.cc:412\] Dynamic Batching: disabled
2023-05-02 10:00:05,019 DEBG 'triton' stderr output:
I0502 10:00:05.019084 647 libfastertransformer.cc:438\] Before Loading Weights:
2023-05-02 10:00:05,254 DEBG 'triton' stderr output:
terminate called after throwing an instance of 'std::runtime\_error'
what(): \[FT\]\[ERROR\] CUDA runtime error: the provided PTX was compiled with an unsupported toolchain. /workspace/build/fastertransformer\_backend/build/\_deps/repo-ft-src/src/fastertransformer/utils/cuda\_utils.h:274 반응형
'Tech' 카테고리의 다른 글
| MongoDB docker 접속하기 (0) | 2024.03.30 |
|---|---|
| 하이패스(하이플러스카드) 인터넷 충전 (2023년 1월 업데이트) (0) | 2023.01.13 |
| [jupyter server / docker / npm] kernel connecting (0) | 2022.11.19 |
| the host does not support password keyboard interactive authentication (0) | 2022.11.19 |
| [도커] syslog가 docker-runtime 로그로 넘칠 때 (0) | 2022.10.15 |